Introduction
This book aims to describe a superior approach to build heavily asynchronous and distributed applications based on the actor model using the elfo framework.
Goals
- Facilitate the development of resilient, fault-tolerant systems.
- Maintain enough performance to meet the needs of low-latency systems.
- Enhance observability through extensive metrics to identify and rectify issues promptly.
- Offer built-in support for exposing log events, dumps, metrics, and trace events.
- Simplify the process of distributing actors across multiple machines.
Non-goals
- Provide the most performant way to communicate between actors.
- Provide any HTTP/WS server functionalities.
Features
- Asynchronous actors equipped with supervision and a customizable life cycle.
- Two-level routing system: between actor groups (pipelining) and inside them (sharding).
- Protocol diversity: actors have the capability to process messages from various protocols, defined in different places.
- Varied communication patterns: regular messages, request-response (TODO: subscriptions).
- Dynamic configuration updates and distribution.
- Suitable for tasks requiring both low latency and high throughput.
- Tracing: every message is assigned a
trace_idwhich spreads system-wide implicitly. - Telemetry through the metrics crate.
- Dumping: messages can be archived for subsequent debugging.
- Effortless distribution across nodes.
- Utilities for straightforward testing.
The term “observability” could be better understood through demonstration. Consider, for example, the concept of metrics:
Comparison aka “Why not X”?
Where X = CSP
Usage of CSP in Rust can be illustrated in the following example:
// "Processes"
async fn read_file(path: &str, tx: Sender<Chunk>) { .. }
async fn decode_chunks(rx: Receiver<Chunk>, tx: Sender<SomeEvent>) { .. }
async fn process_events(rx: Receiver<SomeEvent>) { .. }
// "Channels"
let (chunks_tx, chunks_rx) = channel(100);
let (events_tx, events_rx) = channel(100);
spawn(read_file(path, chunks_tx));
spawn(decode_chunks(chunks_rx, events_tx));
spawn(process_events(events_rx));The CSP approach is a perfect solution that doesn’t require expertise in any frameworks for tools or simple applications with well-defined technical specifications and a small number of communications between processes. If this is your case, just use CSP.
However, complex applications tend to get more and more complicated over time, and their development and maintenance quickly become harder than in the actor model.
Pros of CSP
- Implementation of channels can be chosen by a developer, while actor frameworks determine a mailbox implementation.
- Processes can share the same channel using MPMC channels to implement work-stealing behavior. It’s not an option for actors, where a mailbox is owned by exactly one actor.
Cons of CSP
- Processes in CSP are anonymous, while actors have identities. It means it’s hard to distinguish logs and metrics because processes don’t have names. Thus, the observability of CSP is much worse than that of the actor model.
- Actors are more decoupled; they can be discovered using some sort of service locators and even changed on the fly, e.g., due to restart.
- Actors can be distributed across several machines because they don’t have to send messages directly to a mailbox; they can have a network before it.
- To add more connections between processes, we need to use more channels in one case and combine messages into big enumerations with unrelated items in other cases.
Hello, World
In this chapter we build a small elfo-based application from the ground up.
The system has two actors:
- producer sends a stream of numbers to the aggregator.
- aggregator accumulates a running sum and answers queries about it.
Their interaction is pretty simple:

Note: the full code for this example is available in the elfo repository.
Step 1: Installation
Add the following dependencies in your Cargo.toml:
[dependencies]
# The actor framework itself. The `full` feature enables all built-in batteries:
# configurer, logger, telemeter, dumper, etc.
elfo = { version = "0.2.0-alpha.21", features = ["full"] }
Note:
elfois currently in alpha. Check crates.io for the latest published version and update the version string accordingly.
Put everything in src/main.rs for now. In a real project you would split actors into separate crates, see the Project Structure recipe for guidance, but a single file is fine for learning.
Step 2: Define the protocol
Actors should not depend on each other’s implementation. Instead, they should only depend on shared messages that they exchange. It decouples the actors and makes the system more modular, easier to test.
This decoupling allows you to change the internals of an actor without breaking its clients, and it also makes it easier to reuse actors across projects.
The right place to put shared message types is a protocol module (or, in larger projects, dedicated crates).
mod protocol {
use elfo::prelude::*;
// A plain fire-and-forget command.
// `#[message]` derives elfo::Message, Debug, Clone, Serialize, Deserialize.
#[message]
pub struct AddNum {
pub num: u32,
}
// A request: `ret = u64` means the sender expects a `u64` back.
#[message(ret = u32)]
pub struct GetSum;
}Every type that flows through a mailbox must be annotated with #[message]. The macro enforces necessary trait bounds.
Step 3: Write the producer
The producer sends numbers to the aggregator, then asks for the final sum.
mod producer {
use elfo::prelude::*;
use crate::protocol::*;
pub fn new() -> Blueprint {
ActorGroup::new().exec(|ctx| async move {
// Send numbers.
for num in 0..10u32 {
let _ = ctx.send(AddNum { num }).await;
}
// Ask the aggregator for the current sum and wait for the reply.
match ctx.request(GetSum).resolve().await {
Ok(sum) => tracing::info!(sum, "done"),
Err(err) => tracing::error!(%err, "request failed"),
}
})
}
}ctx.send() is fire-and-forget: it returns as soon as the message lands in the mailbox. ctx.request().resolve().await sends a request and suspends the actor until the response arrives.
Step 4: Write the aggregator
The aggregator keeps a running sum and responds to GetSum queries.
mod aggregator {
use elfo::prelude::*;
use crate::protocol::*;
pub fn new() -> Blueprint {
ActorGroup::new().exec(|mut ctx| async move {
let mut sum = 0u32;
// The main actor loop: receive a message, handle it, repeat.
// Returns `None` (breaking the loop) when the mailbox is closed.
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
AddNum { num } => {
sum += num;
}
// The `(Request, token)` pattern handles a request-response pair.
(GetSum, token) => {
ctx.respond(token, sum);
}
});
}
})
}
}msg! is required because Rust’s built-in match only works with a single type, but a mailbox can carry many different message types. The macro unpacks the envelope and dispatches on the inner type while keeping rustfmt-compatible syntax.
Step 5: Wire up the topology
A topology is the wiring diagram: which actor groups exist, how messages flow between them, and which implementations are used.
fn topology() -> elfo::Topology {
let topology = elfo::Topology::empty();
// Set up built-in actors (logging, config distribution).
let logger = elfo::batteries::logger::init();
let loggers = topology.local("system.loggers");
let configurers = topology.local("system.configurers").entrypoint();
// Declare your own groups.
let producers = topology.local("producers");
let aggregators = topology.local("aggregators");
// Messages sent by the producer are forwarded to the aggregator.
producers.route_all_to(&aggregators);
// Bind blueprints to groups.
producers.mount(producer::new());
aggregators.mount(aggregator::new());
loggers.mount(logger);
configurers.mount(elfo::batteries::configurer::fixture(
&topology,
elfo::config::AnyConfig::default(),
));
topology
}We use route_all_to here to forward every message that the producer sends into the aggregator’s mailbox.
The topology itself doesn’t start anything, so we need to call elfo::init::start() to do it:
#[tokio::main]
async fn main() {
elfo::init::start(topology()).await;
}elfo::init::start blocks until the system shuts down. The configurer starts first, loads config.toml, and then the rest of the actors begin their exec functions.
Step 6: Run the program
$ cargo run
Compiling elfo-examples v0.0.0 (/home/code/fave/elfo/examples)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.91s
Running `target/debug/hello_world`
2026-03-05 09:19:00.228283494 INFO [7661362937482706945] system.configurers/_ - started addr=3/312073041333thread=tokio-runtime-worker
2026-03-05 09:19:00.228325401 INFO [7661362937482706945] system.configurers/_ - status changed status=Normal
2026-03-05 09:19:00.228350429 INFO [7661362937482706945] system.configurers/_ - using a fixture
2026-03-05 09:19:00.228381124 INFO [7661362937482706945] system.configurers/_ - status changed status=Normal details=validating
2026-03-05 09:19:00.228573146 INFO [7661362937482706945] system.configurers/_ - status changed status=Normal details=updating
2026-03-05 09:19:00.228757835 INFO [7661362937482706945] system.configurers/_ - status changed status=Normal
2026-03-05 09:19:00.228768493 INFO [7661362937482706945] system.loggers/_ - started addr=2/312073041334 thread=tokio-runtime-worker
2026-03-05 09:19:00.228788056 INFO [7661362937482706945] system.configurers/_ - groups' configs are updated groups=["system.loggers", "system.configurers", "producers", "aggregators"]
2026-03-05 09:19:00.228800092 INFO [7661362937482706945] producers/_ - started addr=4/312073041335 thread=tokio-runtime-worker
2026-03-05 09:19:00.228843383 INFO [7661362937482706945] system.loggers/_ - status changed status=Normal
2026-03-05 09:19:00.228872997 INFO [7661362937482706945] system.configurers/_ - config updated
2026-03-05 09:19:00.228909195 INFO [7661362937482706945] aggregators/_ - started addr=5/312073041336 thread=tokio-runtime-worker
2026-03-05 09:19:00.228920874 INFO [7661362937482706945] system.init/_ - status changed status=Normal
2026-03-05 09:19:00.228923888 INFO [7661362937482706945] aggregators/_ - status changed status=Normal
2026-03-05 09:19:00.228991147 INFO [7661362937482706945] producers/_ - done sum=45
2026-03-05 09:19:00.229008241 INFO [7661362937482706945] producers/_ - status changed status=Terminated
Press Ctrl+C to gracefully terminate your program.
What’s next?
You now have a working elfo system. The following chapters go deeper into each concept introduced here.
Check the usage example for a more complex application that demonstrates more features of the framework.
Actors
The most important part of the actor model is, of course, the actor itself. It can be challenging to give the exact definition of this term. However, we can define an actor through its properties:
-
An actor is a unit of logic encapsulation
Actors solve a specific task instead of doing it all at once.
-
An actor is a unit of scheduling
Different threads cannot execute the same actor simultaneously1. However, many actors are executed concurrently, often parallel in many threads.
-
An actor is a unit of data encapsulation
Actors shouldn’t share their data with other actors, shouldn’t expose implementation details, etc. Do not communicate by sharing memory; instead, share memory by communicating.
-
An actor is a unit of failure encapsulation
Actors can fail, and it doesn’t affect the work of other actors directly2.
-
An actor is a unit of communication
Actors can communicate with others by sending and receiving messages. Actors are uniquely identified by their addresses.
These properties allow us to build highly scalable and fault-tolerant systems relatively thinkable and straightforwardly without using complex concurrent data structures.
A Mailbox
Every actor has his own mailbox, a queue containing envelopes sent by other actors to this one.
What’s the envelope? The envelope is a wrapper around a message that includes also some useful metadata: the sender’s address, time of sending moment, and some other information that is not so important for now.

A mailbox is the main source of messages for any actor. Messages are handled sequentially.
A mailbox can become full if the corresponding actor doesn’t have time to process the message flow. In this case, the sending actor can decide to drop the message, wait for space in the mailbox or resend after some time. Such strategies will be discussed later.
Functional actors
Let’s define a some simple actor using elfo and figure out what’s happening.
The simplest way to define an actor as a function.
For example, let’s define the simplest counter:
use elfo::prelude::*;
#[message]
pub struct Increment {
pub delta: u32,
}
#[message(ret = u32)]
pub struct GetValue;
pub fn counter() -> Blueprint {
ActorGroup::new().exec(|mut ctx| async move {
// Private state of the actor.
let mut value = 0;
// The main actor loop: receive a message, handle it, repeat.
// Returns `None` and breaks the loop if actor's mailbox is closed
// (usually when the system terminates).
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
Increment { delta } => {
value += delta;
},
// It's a syntax for requests.
(GetValue, token) => {
// ... and responses.
ctx.respond(token, value);
},
})
}
})
}We haven’t discussed actor groups yet, so don’t pay attention for now.
Instead, let’s talk about other things in the example:
ctx.recv()allows us to wait for the next message asynchronously. Thus, if the mailbox is empty, the actor will return control to the scheduler instead of spending CPU cycles or sleeping.msg!allows us to unpack envelopes and match against different types of messages. It’s required, because Rust’smatchmust include patterns for the same data type only. However, we want to support different messages, often defined in different crates. Also, reusing thematchsyntax is highly desired in order to work well with tooling likerustfmtandrust-analyzer.(RequestType, token)is the syntax for handling requests.tokencannot be used more than once, thanks to Rust, so we cannot accidentally respond to the request twice. Also, the compiler will warn if we forget to handletoken. If the token is explicitly dropped without responding, the sending side will get the special error and decide whether it’s normal or not. Note that it is possible to send request as a regular message usingctx.send()instead ofctx.request(). In this case, recipient will get a so-called “forgotten” token. Recipient can still reply using it, but the reply will be discarded before it is sent.
Now let’s define another actor to communicate with the counter:
use elfo::prelude::*;
use counter::{Increment, GetValue};
pub fn sample() -> Blueprint {
ActorGroup::new().exec(|ctx| async move {
// Increment the counter, we aren't interested in errors.
let _ = ctx.send(Increment { delta: 1 }).await;
// ... and again.
let _ = ctx.send(Increment { delta: 3 }).await;
// Request the current counter's value and wait for the response.
if let Ok(value) = ctx.request(GetValue).resolve().await {
tracing::info!(value, "got it!");
}
}
}We haven’t connected our actors in any way, this will be discussed later.
Note: it’s more useful to write complex actors in another way, which will be considered later in the Structural Actors section.
-
Actually, sometimes it’s useful to use
rayonor alternatives. It’s possible inelfoby wrapping threads into an actor’s scope. ↩ -
Actors should be designed to be tolerant to failures of other actors. ↩
Actor lifecycle
An actor goes through several stages in life. Transitions between stages are accompanied by statuses. Statuses help us to understand better what’s happening with actors. So, a good way to understand actor lifecycle is to get familiar with statuses.
Statuses
-
InitializingAn initial status. The actor doesn’t handle incoming messages and is doing some initialization, e.g. subscribing to other actors, collecting an initial state, connecting to DB, etc.
-
NormalThe actor handles incoming messages.
This status appears on first
ctx.(try_)recv()call. -
TerminatingAn actor is preparing to termination, e.g. doing some cleanup, flushing data, etc.
It happens when the actor’s mailbox is closed and all messages are handled. Additionally, if the actor uses
TerminationPolicy::manually, it also happens whenTerminateis received. -
TerminatedA terminal status. The actor’s
exec()finished without errors. -
AlarmingThe actor has some long term problem, but still handles messages, maybe in a special way.
Currently, this status can be set manually only.
-
FailedA terminal status. The actor panicked or his
exec()returnsErr.
Built-in status transitions

The schema doesn’t include the Alarming status, because it can be set only manually for now.
From the point of view of the main actor’s loop:
async fn exec(mut ctx: Context) {
// Status: Initializing
// subscribe to other actors, connect to DB, etc
while let Some(envelope) = ctx.recv().await {
// Status: Normal
// handle messages
}
// Status: Terminating
// make cleanup, flush data, etc
} // Status: Terminated or FailedManual status management
It’s possible to avoid managing statuses totally, built-in logic is reasonable enough. However, with the increasing complexity of actors, it can be helpful to provide more information about the current status.
The basic way to change status:
ctx.set_status(ActorStatus::ALARMING);Also, details can be provided with each status:
ctx.set_status(ActorStatus::INITIALIZING.with_details("loading state"));Subscribing to actor’s statuses
TODO: SubscribeToActorStatuses, ActorStatusReport
Communication
Actors can communicate in many ways depending on the situation and desired guarantees.
Fire and Forget
The most straightforward way is to send a message with minimal guarantees.

However, it’s possible to choose the desired behavior by calling the most appropriate method. All variants can be described by the following template: (try_|unbounded_)send(_to).
Methods with the _to suffix allow to specify a destination address as the first argument. Otherwise, the routing subsystem will be used.
The prefix describes what should happen if the destination mailbox is full:
| Syntax | Error cases | Description |
|---|---|---|
send().await | Closed | Blocks until a destination mailbox has space for new messages |
try_send() | Full, Closed | Returns Full if the mailbox is full |
unbounded_send() | Closed | Ignores the capacity of the mailbox |
All methods can return Closed if the destination actor is closed.
The form send().await is used when desired behavior is backpressure, while try_send() is for actors with predicted latency, when it’s acceptable to lose messages or it can be handled manually. unbounded_send() should be avoided because it can increase mailboxes unpredictably, leading to OOM.
Examples
#[message]
struct SomeMessage;
// Block if the destination mailbox is full.
ctx.send(SomeMessage).await?;
// Do not care if the target actor is closed or full.
ctx.try_send(SomeMessage)?;
// Forcibly push the message into the mailbox.
ctx.unbounded_send(SomeMessage)?;
// Manually implement backpressure, e.g. store messages.
if let Err(err) = ctx.try_send(SomeMessage) {
let msg = err.into_inner(); // msg: SomeMessage
}Blocking Request-Response
Some communications between actors require response message being sent back to the sender.

TODO
Examples
#[message(ret = Result<(), DoSomethingRejected>)]
struct DoSomething;
#[message]
struct DoSomethingRejected(String);
TODONon-blocking Request-Response
 TODO
TODO
State
TODO
Examples
TODO
Subscriptions
TODO
Sources
In the context of the elfo actor system, sources serve as conduits for integrating various streams of incoming messages, such as timers, signals, futures, and streams. They allow for a seamless amalgamation of these additional streams with the messages arriving in the mailbox. Consequently, features like tracing, telemetry, and dumps are uniformly available for both regular and source-generated messages.
You can instantiate sources using dedicated constructors that correspond to different types. It’s important to note that initially, these sources are inactive; they only start generating messages once they are linked to the context through the method ctx.attach(_). This method also returns a handler, facilitating the management of the source. Here is how you can utilize this method:
let unattached_source = SomeSource::new();
let source_handle = ctx.attach(unattached_source);If necessary, you can detach sources at any time by invoking the handle.terminate() method, as shown below:
source_handle.terminate();Under the hood, the storage and utilization of sources are optimized significantly to support multiple sources at the same time, thanks to the unicycle crate. While the system supports an unlimited number of sources without offering backpressure, it’s essential to moderate the usage to prevent potential out-of-memory (OOM) errors.
Intervals
The Interval source is designed to generate messages at a defined time period.
To activate the source, employ either the start(period) or start_after(delay, period) methods, as shown below:
use elfo::time::Interval;
#[message]
struct MyTick; // adhering to best practice by using the 'Tick' suffix
ctx.attach(Interval::new(MyTick))
.start(Duration::from_secs(42));
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
MyTick => { /* handling code here */ },
});
}Adjusting the period
In instances where you need to adjust the timer’s interval, possibly as a result of configuration changes, the interval.set_period() method comes in handy:
use elfo::{time::Interval, messages::ConfigUpdated};
#[message]
struct MyTick; // adhering to best practice by using the 'Tick' suffix
let interval = ctx.attach(Interval::new(MyTick));
interval.start(ctx.config().period);
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
ConfigUpdated => {
interval.set_period(ctx.config().period);
},
MyTick => { /* handling code here */ },
});
}To halt the timer without detaching the interval, use interval.stop(). This method differs from interval.terminate() as it allows for the possibility to restart the timer later using interval.start(period) or start_after(delay, period) methods.
It’s essential to note that calling interval.start() at different points can yield varied behavior compared to invoking interval.set_period() on an already active interval. The interval.set_period() method solely modifies the existing interval without resetting the time origin, contrasting with the rescheduling functions (start_* methods). Here’s a visual representation to illustrate the differences between these two approaches:
set_period(10s): | 5s | 5s | 5s | # 10s | 10s |
start(10s): | 5s | 5s | 5s | # 10s | 10s |
#
called here
Tracing
Every message starts a new trace, thus a new TraceId is generated and assigned to the current scope.
Delays
The Delay source is designed to generate one message after a specified time:
use elfo::time::Delay;
#[message]
struct MyTick; // adhering to best practice by using the 'Tick' suffix
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
SomeEvent => {
ctx.attach(Delay::new(ctx.config().delay, MyTick));
},
MyTick => { /* handling code here */ },
});
}This source is detached automatically after emitting a message, there is no way to reschedule it. To stop delay before emitting, use the delay.terminate() method.
Tracing
The emitted message continues the current trace. The reason for it is that this source is usually used for delaying specific action, so logically it’s continues the current trace.
Signals
The Signal source is designed to generate a message once a signal is received:
use elfo::signal::{Signal, SignalKind};
#[message]
struct ReloadFile;
ctx.attach(Signal::new(SignalKind::UnixHangup, ReloadFile));
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
ReloadFile => { /* handling code here */ },
});
}It’s based on the tokio implementation, so it should be useful to read about caveats.
Tracing
Every message starts a new trace, thus a new trace id is generated and assigned to the current scope.
Streams
The Stream source is designed to wrap existing futures/streams of messages. Items can be either any instance of Message or Result<impl Message, impl Message>.
Once stream is exhausted, it’s detached automatically.
Futures
Utilize Stream::once() when implementing subtasks such as initiating a background request:
use elfo::stream::Stream;
#[message]
struct DataFetched(u32);
#[message]
struct FetchDataFailed(String);
async fn fetch_data() -> Result<DataFetched, FetchDataFailed> {
// ... implementation details ...
}
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
SomeEvent => {
ctx.attach(Stream::once(fetch_data()));
},
DataFetched => { /* handling code here */ },
FetchDataFailed => { /* error handling code here */ },
});
}futures::Stream
Stream::from_futures03 is used to wrap existing futures::Stream:
use elfo::stream::Stream;
#[message]
struct MyItem(u32);
let stream = futures::stream::iter(vec![MyItem(0), MyItem(1)]);
ctx.attach(Stream::from_futures03(stream));
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
MyItem => { /* handling code here */ },
});
}To produce messages of different types from the stream, it’s possible to cast specific messages into AnyMessage (undocumented for now):
futures::stream::iter(vec![MyItem(0).upcast(), AnotherItem.upcast()])Generators
Stream::generate is an alternative to the async-stream crate, offering the same functionality without the need for macros, thereby being formatted by rustfmt:
use elfo::stream::Stream;
#[message]
struct SomeMessage(u32);
#[message]
struct AnotherMessage;
ctx.attach(Stream::generate(|mut e| async move {
e.emit(SomeMessage(42)).await;
e.emit(AnotherMessage).await;
}));
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
SomeMessage(no) | AnotherMessage => { /* handling code here */ },
});
}Tracing
The trace handling varies depending upon the method used to create the stream:
- For
Stream::from_futures03(): each message initiates a new trace. - For
Stream::once()andStream::generate(): the existing trace is continued.
To override the current trace, leverage scope::set_trace_id() at any time.
Structural Actors
Organizing actors using the functions can quickly escalate in complexity, making scalability an issue. A more streamlined approach is to employ structural actors, where all actor-related code is consolidated within a specific actor structure. Notably, elfo does not provide any Actor trait, precluding constructs like impl Actor for Counter. As such, the following code serves as a flexible pattern that can be adapted as required.
Complex actors require decomposition into multiple related functions, which scales worse with functional actors considered earlier. The better way to organize actors is to use so-called structural actors. The idea is to write all actor-related code in some specific actor structure. elfo has no any Actor trait, so it’s impossible to see impl Actor for Counter or something like this. Thus, the following code is some sort of pattern and can be modified if needed.
To illustrate, let’s reconfigure the counter actor to adopt a structural style. The protocol code remains unchanged:
#[message]
pub struct Increment {
pub delta: u32,
}
#[message(ret = u32)]
pub struct GetValue;Here’s how the counter’s code transitions to this new approach:
use elfo::prelude::*;
// This constitutes the sole public API of the actor.
// It gets invoked as `counters.mount(counter::new())` in services.
pub fn new() -> Blueprint {
ActorGroup::new().exec(|mut ctx| Counter::new(ctx).main())
}
struct Counter {
ctx: Context,
value: u32,
}
impl Counter {
fn new(ctx: Context) -> Self {
Self {
ctx,
value: 0,
}
}
async fn main(mut self) {
while let Some(envelope) = self.ctx.recv().await {
msg!(match envelope {
// More elaborate handling code can be delegated to methods.
// These methods can easily be async.
msg @ Increment => self.on_increment(msg),
// Simpler code, however, can still be processed directly here.
(GetValue, token) => {
self.ctx.respond(token, self.value);
},
})
}
}
fn on_increment(&mut self, msg: Increment) {
self.value += msg.delta;
}
}This refactoring can significantly enhances readability in many cases, making it an advantageous choice for complex actors.
Furthermore, sources can be encapsulated within the actor structure, facilitating operation from methods. To illustrate, we can introduce a feature that outputs the current value when the counter stabilizes (i.e. remains unchanged for a period). Here’s how:
use std::{time::Duration, mem};
use elfo::time::Delay;
struct Counter {
ctx: Context,
stable_delay: Delay<StableTick>,
value: u32,
}
#[message]
struct StableTick;
impl Counter {
fn new(mut ctx: Context) -> Self {
let delay = Delay::new(Duration::from_secs(1), StableTick);
Self {
value: 0,
stable_delay: ctx.attach(delay),
ctx,
}
}
async fn main(mut self) {
// ...
StableTick => self.on_stable(),
// ...
}
fn on_increment(&mut self, msg: Increment) {
self.value += msg.delta;
self.stable_delay.reset();
}
fn on_stable(&self) {
tracing::info!("counter is stable");
}
}Actor Groups
Before talking about actor groups, we need to consider another vital topic: scaling.
Scaling
Scaling is helpful both to increase throughput of a system and reduce latency.
Two known ways to do scaling are pipelining and sharding.
Pipelining
Pipelining implies dividing the system into several sequential parts. Thus, instead of doing all work in one actor, different actors do the work in parts.

Pipelining increases minimal possible latency because of overhead costs but can reduce maximal latency because of parallel execution of different parts. Throughput is the minimum of parts’ throughputs. However, total throughput increases because every actor in the pipeline does less work.
Usually, it’s not necessary to think about pipelining because well-designed systems are already divided into multiple actors according to their responsibilities, not because of performance requirements.
Sharding
Sharding implies multiple running actors with the same, possible parameterized, code and responsibility.

Sharding requires some work to route messages to the corresponding shard. Thus, throughput is increased sublinearly. Similarly to pipelining, maximal latency is reduced because arrival messages see ahead of themself fewer messages.
Actor Groups
Actor groups in elfo are a solution for the sharding problem. Each actor has some actor key, a unique label inside a group, that can be used for routing purposes.
The group’s router is not an actor but some shared code that’s executed on sending side to determine which actor should receive a message. Usually, routers are stateless; thus, this approach is more performant and scalable than routers implemented as separate actors.

elfo doesn’t support running actors without actor groups. Instead, it’s ok to use groups with only one actor inside if it’s meaningless to do sharding for now.
Note that actor keys can be arbitrary structures, not mandatory strings.
See the next chapter to get more details about routing.
Stability
TODO: move to the first usage.
It’s useful to know the term stability. Stable systems are restricted only by input rate and don’t have 100% utilization. We usually want to minimize latency in such systems while keeping throughput higher than real-life requirements. Most of systems are supposed to be stable and have predictable latency. Unstable systems have 100% utilization and reach their throughput. For instance, ETL systems.
Routing
Routing is the process of searching for the actor that will handle a sent message. In order to append the message to his mailbox, we need to discover the actor’s address.
elfo offers a two-level routing system. What does it mean? Messages can pass through up to two steps of routing, depending on used methods, as shown on the following diagram:

- If we don’t know any address (
ctx.(try_|unbounded_)send(msg)andctx.request(msg)), the inter-group router is called to determine which groups are interested in the message. Then, the corresponding inner-group router is called for each interested group to decide which shards should receive the message. - Only the inner-group router is called if we already know a group’s address (
ctx.(try_|unbounded_)send_to(group_addr, msg)andctx.request_to(group_addr, msg)). - If we already know an actor’s address (
ctx.(try_|unbounded_)send_to(actor_addr, msg)andctx.request_to(actor_addr, msg)), nothing additional is done because we already know which actor should handle the message.
Note that if several actors are interested in the message, each receives a copy of the message. It’s ok for messages without heap-allocated fields or for rare messages, but for the big ones consider wrapping into Arc to reduce the clone() overhead.
Inter-group routing
Inter-group routing is responsible for connecting actor groups among themselves.
Let’s consider the following architecture scheme:

Actor groups and connections between them are defined in so-called “topology”:
fn topology(config_path: &str) -> elfo::Topology {
let topology = elfo::Topology::empty();
let logger = elfo::logger::init();
// Define system groups.
let loggers = topology.local("system.loggers");
let telemeters = topology.local("system.telemeters");
let dumpers = topology.local("system.dumpers");
let pingers = topology.local("system.pingers");
let configurers = topology.local("system.configurers").entrypoint();
// Define user groups.
let group_a = topology.local("group_a");
let group_b = topology.local("group_b");
let group_c = topology.local("group_c");
// Define connections between user actor groups.
group_a.route_to(&group_b, |e| { // "e" means "Envelope"
msg!(match e {
MessageX | MessageY => true,
_ => false,
})
});
group_a.route_to(&group_c, |e| {
msg!(match e {
MessageX => true,
_ => false,
})
});
group_b.route_to(&group_c, |e| {
msg!(match e {
MessageZ => true,
_ => false,
})
});
group_c.route_to(&group_a, |e| {
msg!(match e {
MessageW => true,
_ => false,
})
});
// Mount specific implementations.
loggers.mount(logger);
telemeters.mount(elfo::telemeter::new());
dumpers.mount(elfo::dumper::new());
pingers.mount(elfo::pinger::new(&topology));
// Actors can use `topology` as a service locator.
// Usually it should be used for utilities only.
configurers.mount(elfo::configurer::from_path(&topology, config_path));
group_a.mount(group_a::new());
group_b.mount(group_b::new());
group_c.mount(group_c::new());
topology
}Not all messages should be specified at this level. Usually, only requests and some multicast events are specified here, but not messages that will be passed directly, such as responses or events of subscriptions.
Inner-group routing
Inner-group routing is responsible for choosing which shards should handle incoming messages.
The inner-group router is defined next to the actor implementation, in the group declaration.
Stateless router
use elfo::routers::{Outcome, MapRouter};
ActorGroup::new()
.router(MapRouter::new(|e| {
msg!(match e {
MessageX { key, .. } => Outcome::Unicast(key),
MessageY { keys, .. } => Outcome::Multicast(keys.to_vec()),
MessageZ => Outcome::Broadcast,
_ => Outcome::Default,
})
}))
.exec(exec);Possible Outcome’s variants:
Outcome::Unicastsends the message only to the actor with a specified key. If there is no active or restarting actor for the key, the new one will be started.Outcome::GentleUnicastworks likeOutcome::Unicast, but doesn’t lead to spawning new actors, instead a message is discarded.Outcome::Multicastsends to several actors. New actors will be started.Outcome::GentleMulticastworks likeOutcome::Multicast, but doesn’t lead to spawning new actors, instead a message is discarded.Outcome::Broadcastsends to all active actors.Outcome::Discarddrops the message (that leads to an error on sending side).Outcome::Defaultbehaviour depends on the message type:Outcome::DiscardforValidateConfigmessage.Outcome::Broadcastfor all other system messages (such asUpdateConfig,Terminate, etc).Outcome::Discardfor user-defined messages.
Stateful router
Sometimes we need to use a router with rarely changing state. If the state should be changed often, consider using a dedicated actor as a router.
To create a stateful router use the MapRouter::with_state constructor. Note that the state type should implement Default, Send and Sync.
ActorGroup::new()
.router(MapRouter::with_state(
// Called if the config is changed.
|config: &Config, state| make_new_state(..),
// The routing function.
|e, state| {
msg!(match e { .. })
}
))
.exec(exec);The state is recreated every time when the config is changed. Useful when all needed information (e.g. a list of actors) can be extracted from the config. Note that recreation doesn’t block execution; the state is atomically replaced only once make_new_state(..) is finished.
Configuration
Each actor group can have its own configuration section in the TOML config file. The section name corresponds to the group’s name as registered in the topology.
Structure
A typical config file looks like this:
# Properties defined here are merged into every actor group's section.
[common]
system.logging.max_level = "Info"
# User-defined config fields for the group named in the topology.
[some_group_name]
some_param = 42
# The system.* sub-section is reserved for elfo's own settings.
system.telemetry.per_actor_key = true
The [common] section is special: its contents are merged into every actor group’s config. Thus, it can be used to set defaults that apply to all groups, while still allowing individual groups to override them.
User config
Actor groups declare their own config by calling .config::<T>() on ActorGroup. T must implement serde::Deserialize and Debug.
#[derive(Debug, Deserialize)]
struct MyConfig {
interval: Duration,
threshold: u64,
}
ActorGroup::new().config::<MyConfig>().exec(my_actor)The deserialized value is accessed inside the actor via ctx.config(), which always returns the latest validated and applied version.
Secrets
Fields that contain sensitive data (passwords, API keys, etc.) should be wrapped in elfo::config::Secret<T>. This suppresses the field’s value in logs and dumps while keeping full access to the underlying value in code and allowing it to be sent over network.
use elfo::config::Secret;
#[derive(Debug, Deserialize)]
struct Config {
password: Secret<String>,
}Handling config updates
When the config file is changed and the system reloads it (e.g. on SIGHUP), actors receive the UpdateConfig message, which silently updates the value returned by ctx.config() and transformed into the ConfigUpdated message. This allows actors to react to the new config values without needing to restart the whole system:
use elfo::{
prelude::*,
messages::ConfigUpdated,
time::Interval,
};
async fn my_actor(mut ctx: Context<MyConfig>) {
let interval = ctx.attach(Interval::new(Tick));
interval.start(ctx.config().interval);
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
ConfigUpdated => {
// React to the new config values.
interval.set_period(ctx.config().interval);
}
Tick => { /* ... */ }
});
}
}Validating config updates
Actors have a chance to validate the incoming config on reconfiguration by receiving the ValidateConfig request. Any structural / type-level validation should happen at deserialization time (consider the validator crate for that). ValidateConfig is for checks requiring the access to actors’ state. Responding Ok(()) accepts the config; Err(reason) rejects the whole reload. If the message is simply discarded (no response), validation is considered passed.
use elfo::{
messages::{ConfigUpdated, ValidateConfig},
prelude::*,
};
msg!(match envelope {
(ValidateConfig { config, .. }, token) => {
let new = ctx.unpack_config(&config);
// Perform any dynamic validation here.
ctx.respond(token, Ok(()));
}
})Note that ValidateConfig is discarded by the default router. So, you should explicitly allow it in the router:
ActorGroup::new().router(MapRouter::new(|e| {
msg!(match e {
ValidateConfig => Outcome::GentleUnicast(MyKey),
_ => Outcome::Default,
})
}))See the reconfiguration page for more details.
System config
Every actor group’s config section may contain a system.* sub-table that controls built-in elfo behaviour:
| Sub-section | Struct | Description |
|---|---|---|
system.mailbox | MailboxConfig | Mailbox capacity |
system.telemetry | TelemetryConfig | Metrics grouping |
system.logging | LoggingConfig | Log level and rate limits |
system.dumping | DumpingConfig | Message dumping on/off and rate |
system.restart_policy | RestartPolicyConfig | Configuration of restart policies |
Batteries’ config
Batteries (built-in actors provided by elfo) exports their own configuration.
Supervision
Startup
Once the system is started, the system.init actor starts all actors marked as entrypoint() in the topology. Usually, it’s only the system.configurers group. Entry points must have empty configs.
Then, system.configurers loads the config file and sends UpdateConfig to all actor groups. This message is usually used to start any remaining actors in the system. Thus, you need to define routing for UpdateConfig with either Outcome::Unicast or Outcome::Multicast for actor keys you want to start on startup.

Note that the actor system terminates immediately if the config file is invalid at startup (elfo::start() returns an error).
Reconfiguration
Reconfiguration can be caused in several cases:
- The configurer receives
ReloadConfigsorTryRealodConfigs. - The process receives
SIGHUP, it’s an equivalent to receivingReloadConfigs::default(). - The process receives
SIGUSR2, it’s an equivalent to receivingReloadConfigs::default().with_force(true).
What’s the difference between default behavior and with_force(true) one? By default, group’s up-to-date configs aren’t sent across the system. In the force mode, all configs are updated, even unchanged ones.
The reconfiguration process consists of several stages:

- Config validation: the configurer sends the
ValidateConfigrequest to all groups and waits for responses. If all groups respondOk(_)or discard the request (which is the default behaviour), the config is considered valid and the configurer proceeds to the next step. - Config update: the configurer sends
UpdateConfigto all groups. Note that it is sent as a regular message, rather than request, making config update asynchronous. System does not wait for all configs to apply before finishing this stage and it is possible for an actor to fail while applying the new config. Despite actor failures, any further actors spawned (or restarted) will have the new config available for them.
More information about configs and the reconfiguration process is available on the corresponding page.
Restart
Restart policies
Three restart policies are implemented now:
RestartPolicy::never(by default) — actors are never restarted. However, they can be started again on incoming messages.RestartPolicy::on_failure— actors are restarted only after failures (theexecfunction returnedError panicked).RestartPolicy::always— actors are restarted after termination (theexecfunction returnedOkor()) and failures.
If the actor is scheduled to be restarted, incoming messages cannot spawn another actor for his key.
The restart policy can be chosen while creating an ActorGroup. This is the default restart policy for the group, which will be used if not overridden.
use elfo::{RestartPolicy, RestartParams, ActorGroup};
ActorGroup::new().restart_policy(RestartPolicy::always(RestartParams::new(...)))
ActorGroup::new().restart_policy(RestartPolicy::on_failure(RestartParams::new(...)))
ActorGroup::new().restart_policy(RestartPolicy::never())The group restart policy can be overridden separately for each actor group in the configuration:
[group_a.system.restart_policy]
when = "Never" # Override group policy on `config_update` with `RestartPolicy::never()`.
[group_b.system.restart_policy]
# Override the group policy on `config_update` with `RestartPolicy::always(...)`.
when = "Always" # or "OnFailure".
# Configuration details for the RestartParams of the backoff strategy in the restart policy.
# The parameters are described further in the chapter.
min_backoff = "5s" # Required.
max_backoff = "30s" # Required.
factor = "2.0" # Optional.
max_retries = "20" # Optional.
auto_reset = "5s" # Optional.
[group_c]
# If the restart policy is not specified, the restart policy from the blueprint will be used.
Additionally, each actor can further override its restart policy through the actor’s context:
// Override the group policy with the actor's policy, which is applicable only for this lifecycle.
ctx.set_restart_policy(RestartPolicy::...);
// Restore the group policy from the configuration (if specified), or use the default group policy.
ctx.set_restart_policy(None);Repetitive restarts
Repetitive restarts are limited by an exponential backoff strategy. The delay for each subsequent retry is calculated as follows:
delay = min(min_backoff * pow(factor, power), max_backoff)
power = power + 1
So for example, when factor is set to 2, min_backoff is set to 4, and max_backoff is set to 36, and power is set to 0,
this will result in the following sequence of delays: [4, 8, 16, 32, 36].
The backoff strategy is configured by passing a RestartParams to one of the restart policies, either RestartPolicy::on_failure or RestartPolicy::always, upon creation.
The required parameters for RestartParams are as follows:
min_backoff- Minimal restart time limit.max_backoff- Maximum restart time limit.
The RestartParams can be further configured with the following optional parameters:
factor- The value to multiply the current delay with for each retry attempt. Default value is2.0.max_retries- The limit on retry attempts, after which the actor stops attempts to restart. The default value isNonZeroU64::MAX, which effectively means unlimited retries.auto_reset- The duration of an actor’s lifecycle sufficient to deem the actor healthy. The default value ismin_backoff. After this duration elapses, the backoff strategy automatically resets. The following restart will occur without delays and will be considered the first retry.
Subsequent restarts will have delays calculated using the formula above, with the power starting from 0.
Termination
System termination is started by the system.init actor in several cases:
- Received
SIGTERMorSIGINTsignals, Unix only. - Received
CTRL_C_EVENTorCTRL_BREAK_EVENTevents, Windows only. - Too high memory usage, Unix only. Now it’s 90% (ratio of RSS to total memory) and not configurable (elfo#60).
The process consists of several stages:

system.initsends to all user-defined groups “polite”Terminate::default()message.- Groups’ supervisors stop spawning new actors.
Terminateis routed as a usual message withOutcome::Broadcastby default.- For
TerminationPolicy::closing(by default): the mailbox is closed instantly,ctx.recv()returnsNoneafter already stored messages. - For
TerminationPolicy::manually: the mailbox isn’t closed,ctx.recv()returnsTerminatein order to handle in on your own. Usectx.close()to close the mailbox.
- If some groups haven’t terminated after 30s,
system.initsendsTerminate::closing()message.Terminateis routed as a usual message withOutcome::Broadcastby default.- For any policy, the mailbox is closed instantly,
ctx.recv()returnsNoneafter already stored messages.
- If some groups haven’t terminated after another 15s,
system.initstops waiting for that groups. - Repeat the above stages for system groups.
Timeouts above aren’t configurable for now (elfo#61).
The termination policy can be chosen while creating ActorGroup:
use elfo::group::{TerminationPolicy, ActorGroup};
ActorGroup::new().termination_policy(TerminationPolicy::closing())
ActorGroup::new().termination_policy(TerminationPolicy::manually())Observability
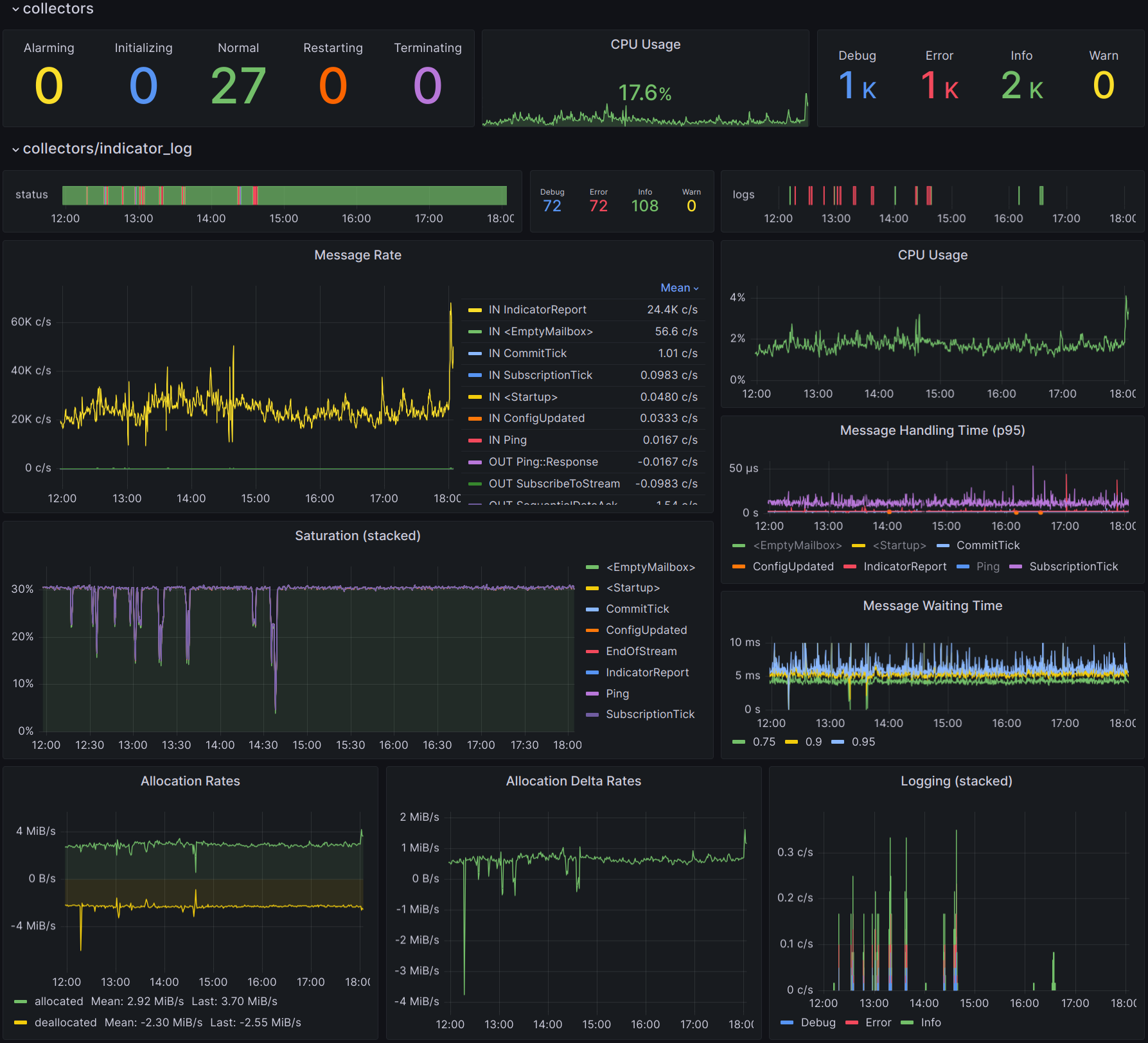
In production systems, knowing that the code runs is not enough, you need to know how it runs. Observability answers questions like: how actors are processing requests? What happened in the system a minute before the outage? Without good tooling, these questions can only be answered by adding more logging or metrics after the fact, redeploying, and waiting for the problem to happen again.
In a distributed actor system these challenges are amplified. Requests hop across actors and nodes, work is performed concurrently, and a single logical operation may touch dozens of components. Retrofitting observability onto such a system rarely works well: developers forget to propagate context, log lines lack the identity of the actor that produced them, rate limits have to be re-implemented in every project and so on.
This is why elfo treats observability as a first-class concern implemented at the framework level. Things like logging, telemetry, and message dumping are built-in batteries that work correctly out of the box and, critically, they work implicitly. Actor code does not need to pass meta to logs or metrics handles, or a trace context through every function call. The framework provides that context automatically.
Scope
The mechanism behind this implicit context is Scope.
Every task running inside elfo has a Scope installed as a task-local value. Actors get one automatically; by default, there is exactly one Scope per running actor task. It carries everything the observability machinery needs: actor location, identity, current trace, limits for logging and dumping and so on.
When a tracing::info! call fires inside an actor, the logging layer reads the current task’s Scope to decide whether the event passes the configured level, whether it exceeds the rate limit, and which actor group and key to attach to the log line, all without the actor knowing any of this is happening.
Scope propagation
Sometimes you need to run code outside the normal actor task, for instance, in tokio::task::spawn_blocking. If you use elfo’s own elfo::task::spawn_blocking, the scope is propagated automatically:
// The scope of the current actor is automatically installed on the blocking thread.
// Logs, metrics, and dumps inside the closure are attributed to this actor.
elfo::task::spawn_blocking(|| {
tracing::info!("running on a blocking thread, still attributed correctly");
do_heavy_work()
}).await?;If you need to spawn a task manually, for example using a third-party executor or a raw tokio::task::spawn_blocking, you can capture the current scope with elfo::scope::expose() and re-install it with Scope::sync_within (for blocking code) or Scope::within (for async code):
let scope = elfo::scope::expose(); // clone the current scope out of TLS
tokio::task::spawn_blocking(move || {
scope.sync_within(|| {
// Everything here runs with the actor's scope installed.
tracing::info!("still attributed to the right actor");
do_heavy_work()
})
}).await?;scope::expose() panics if called outside the actor system. Use scope::try_expose() in code that may run in both contexts.
Logging
Elfo uses the tracing crate as its logging interface. Actor code emits log events with the standard tracing macros, so no elfo-specific API is needed.
Thus, it’s possible to install and use a custom tracing::Subscriber. However, elfo provides the elfo-logger actor with the subscriber implementation. Because it’s a normal actor, it can be configured and observed. Traditionally, elfo-logger is mounted at the system.loggers actor group.
Any events emitted anywhere are captured by the subscriber, stored in the queue of the elfo-logger actor, and then processed by the logger’s main loop according to its configuration.

Setting up the logger
To enable logging, call elfo::batteries::logger::init() before building your topology and mount the returned Blueprint at the system.loggers group:
fn topology() -> elfo::Topology {
let topology = elfo::Topology::empty();
// Registers the global tracing subscriber; returns a Blueprint.
let logger = elfo::batteries::logger::init();
// From this point, every event emitted anywhere is captured.
let loggers = topology.local("system.loggers");
let configurers = topology.local("system.configurers").entrypoint();
// ... user groups ...
loggers.mount(logger);
configurers.mount(..);
topology
}Note:
init()also respects theRUST_LOGenvironment variable (viatracing-subscriber’sEnvFilter) when theenv-filterfeature is enabled, which is the default.
Usage
Use regular macros (tracing::info!, tracing::warn! etc) directly in your actors:
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
MyRequest { value } => {
tracing::info!(value, "received a request!");
}
});
}By default, every log line written by elfo-logger has the following structure:
<timestamp> <level> [<trace_id>] <actor_group>/<actor_key> - <message>\t<fields>
Example output from a running system:
2026-03-05 09:19:00.228757835 INFO [7661362937482706945] system.configurers/_ - status changed status=Normal details=updating
2026-03-05 09:19:00.228988147 INFO [7661362937482706945] producers/_ - done sum=45
Configuration
The logging configuration is defined in the system.logging subsection:
[some_group]
system.logging.max_level = "Info"
system.logging.max_rate_per_level = 1_000
To configure elfo-logger itself, use the [system.loggers] section:
[system.loggers]
sink = "File"
path = "app.log"
See the rustdoc for more details.
Note: all configuration is hot-reloaded: when the config file is reloaded (e.g. on
SIGHUP), the logger reconfigures itself without restarting.
Composing a custom subscriber
If you need to compose elfo’s logger with additional layers, use elfo::batteries::logger::new() instead of init(). It returns the raw parts so you can assemble your own subscriber:
let (blueprint, scope_filter, capture_layer) = elfo::batteries::logger::new();
tracing_subscriber::registry()
.with(my_extra_layer)
.with(capture_layer.with_filter(scope_filter))
.init();
loggers.mount(blueprint);See the Tokio Console chapter for a concrete example of this pattern.
Telemetry
Introduction
TODO: metrics crate, metric types.
All metrics are provided with the actor_group and, optionally, actor_key labels. The last one is added for actor groups with enabled system.telemetry.per_actor_key option.
Read more information about metric types.
TODO: tips, prefer increment_gauge! over gauge!
Configuration
Telemetry can be configured separately for each actor group. Possible options and their default values:
[some_group]
system.telemetry.per_actor_group = true
system.telemetry.per_actor_key = false
Note that using per_actor_key can highly increase a number of metrics. Use it only for low cardinality groups.
TODO: elfo-telemeter config.
Built-in metrics
elfo is shipped with a lot of metrics. All of them start with the elfo_ prefix to avoid collisions with user defined metrics.
Statuses
-
Gauge
elfo_active_actors{status}The number of active actors in the specified status.
-
Gauge
elfo_restarting_actorsThe number of actors that will be restarted after some time.
-
Counter
elfo_actor_status_changes_total{status}The number of transitions into the specified status.
Messages
-
Counter
elfo_sent_messages_total{message, protocol}The number of sent messages.
-
Summary
elfo_message_handling_time_seconds{message, protocol}Spent time on handling the message, measured between
(try_)recv()calls. Used to detect slow handlers. -
Summary
elfo_message_waiting_time_secondsElapsed time between
send()and correspondingrecv()calls. Usually it represents a time that a message spends in a mailbox. Used to detect places that should be sharded to reduce a total latency. -
Summary
elfo_busy_time_secondsSpent time on polling a task with an actor. More precisely, the time for which the task executor is blocked. Equals to CPU time if blocking IO isn’t used.
Log events
-
Counter
elfo_emitted_events_total{level}The number of emitted events per level (
Error,Warn,Info,Debug,Trace). -
Counter
elfo_limited_events_total{level}The number of events that haven’t been emitted because the limit was reached.
-
Counter
elfo_lost_events_total{level}The number of events that hasn’t been emitted because the event storage is full.
Dump events
-
Counter
elfo_emitted_dumps_totalThe number of emitted dumps.
-
Counter
elfo_limited_dumps_totalThe number of dumps that haven’t been emitted because the limit was reached.
-
Counter
elfo_lost_dumps_totalThe number of dumps that hasn’t been emitted because the dump storage is full.
Other metrics
TODO: specific to elfo-logger, elfo-dumper, elfo_telemeter
Derived metrics
Statuses
TODO
Incoming/outgoing rate
TODO
rate(elfo_message_handling_time_seconds_count{actor_group="${actor_group:raw}",actor_key=""}[$__rate_interval])
Waiting time
TODO
rate(elfo_message_waiting_time_seconds{actor_group="${actor_group:raw}",actor_key="",quantile=~"0.75|0.9|0.95"}[$__rate_interval])
Utilization
TODO
rate(elfo_message_handling_time_seconds_sum{actor_group="${actor_group:raw}",actor_key=""}[$__rate_interval])
Executor utilization (≈ CPU usage)
TODO
The time for which the task executor is blocked. Equals to CPU time if blocking IO isn’t used.
rate(elfo_busy_time_seconds_sum[$__rate_interval])
Dashboards
TODO
Implementation details
TODO
Dumping
Introduction
Dumping is the process of storing incoming and outgoing messages for every actor, including ones from mailboxes and all other sources like timers, streams, and so on. The primary purpose is future tracing, but it also can be used for regression testing.
Dumping has a lot of common with logging, but it’s more efficient and optimized for storing a lot of messages, so it has high throughput requirements instead of low latency like in the logging task, where records are supposed to be delivered as soon as possible, especially warnings and errors.
Usage
Enable dumping
Dumping is disabled by default until the topology contains the system.dumpers group.
Elfo provides the default implementation for such group, that’s available with the full feature and exported as elfo::dumper:
let topology = elfo::Topology::empty();
let dumpers = topology.local("system.dumpers");
// ...
dumpers.mount(elfo::dumper::new());Besides this, the path to a dump file must be specified in the config:
[system.dumpers]
path = "path/to/dump/file.dump"
Configure dumping on a per-group basis
Dumping settings can be specified for each actor group individually. Note that the settings can be changed and applied on the fly.
Example:
[some_actor_group]
system.dumping.disabled = true # false by default
system.dumping.rate_limit = 100500 # 100000 by default
Dumps above the rate limit are lost, but the sequence number is incremented anyway to detect missed messages later.
Configure dumping on a per-message basis
Simply add the message(dumping = "disabled") attribute to the message. Another and default value of the attribute is "full".
#[message(dumping = "disabled")]
pub struct SomethingHappened {
// ...
}Shorten fields of a message
Sometimes the content of messages is too large, for instance, in writing a backend for graph plotting, where every response can contain thousands of points. We don’t want to lose additional information about responses, but saving whole messages is very expensive in this case.
For this situation, elfo provides a helper to hide specified fields during serialization, but only in the dumping context. So, these messages still will be properly sent over the network, where serialization is used too.
#[message]
pub struct ChunkProduced {
pub graph_id: GraphId,
#[serde(serialize_with = "elfo::dumping::hide")]
pub points: Vec<(f64, f64)>, // will be dumped as "<hidden>"
}Such messages cannot be deserialized properly; that’s ok until they are used as input for regression testing.
Metrics
TODO
Local storage
The default implementation of dumpers writes all dumps to a file on the local file system.
Even home-purpose SSDs can achieve 3GiB/s in 2021, which should be more than enough to avoid a bottleneck in this place.
Dumps are stored in an uncompressed way so that they can take a lot of space. So, it’s essential to rotate the dump file timely and delete outdated ones.
Note that message ordering between actor groups (and even inside the same actor) can be easily violated because of implementation details. Therefore, in the case of reading from local dump files, you should sort rows by the timestamp field.
The structure of dump files
Dump files contain messages in the newline-delimited JSON format. Each line is object containing the following properties:
g— an actor group’s namek— an optional actor’s keyn— node_nos—sequence_no, unique inside an actor groupt—trace_idts— timestampd— direction, “In” or “Out”cl— an optional classmn— a message’s namemp— a message’s protocol, usually a crate, which contains the messagemk— a message’s kind, “Regular”, “Request” or “Response”m— a nullable message’s bodyc— an optional correlation id, which links requests with corresponding responses
Terms:
- optional means that the property can be omitted, but if it’s present, then its value isn’t
null. - nullable means that the property is present always, but the value can be
null.
The sequence_no field can be used to detect missed messages because of limiting.
TODO: note about classes
Dump file rotation
elfo::dumper doesn’t use any kind of partitioning and relies on an external file rotation mechanism instead. It means some additional configuration is required, but it provides more flexibility and simplifies the dumper.
The dumper listens to the SIGHUP signal to reopen the active dump file. Besides this, the dumper accepts the elfo::dumper::ReopenDumpFile command.
The most popular solution for file rotation is, of course, logrotate.
TODO: logrotate config
Tip: if dumps are not supposed to be delivered to DB, use hard links to save the dump file for later discovery and avoid deletion.
Remote storage
Depending on your goals, you may or may not want to send your dump files to remote file storage. It can highly improve search capabilities (primarily because of indexing trace_id) and space usage but requires additional infrastructure for dumping. Usually, it’s ok for many services to use only local storage. Dumps are stored in a time-ordered way and, thanks to the structure of trace_id, can be used for good enough search. However, elfo doesn’t provide the utility to search these files for now.
Ok, so you want to store dumps in DB. The right choice, if you can afford it. What should you do?
The common schema looks like

TODO: add a link to the example with vector.dev and clickhouse
Implementation details
TODO: implementation has been changed a lot, need to update the section
At a top level, dumping is separated into two parts: the dumping subsystem and the dumper.
The dumping subsystem is based on sharded in-memory storage containing a limited queue of messages. We use a predefined number of shards for now, but we will likely use the number of available cores in the future. Every thread writes to its dedicated shard. Such an approach reduces contention and false sharing between threads.

The dumper sequentially, in a round-robin way, replaces the shard’s queue with the extra one, then reads and serializes all messages and writes them to the dump file. All this work happens on a timer tick. Firstly, it’s one of the simplest ways to get appropriate batching. Secondly, because the dumper uses tokio::task::spawn_blocking and blocking writes insides, that’s more effective than using async tokio::fs directly. The timer approach allows us to reduce the impact on the tokio executor. However, this behavior is going to be improved for environments with io_uring in the future.
The dumper holds the lock only for a small amount of time to replace the queue inside a shard with another one, which was drained by the dumper on the previous tick. Thus, the actual number of queues is one more than shards.
All actors in a group share the same handler with some common things like sequence_no generator and rate limiter. Whenever an actor sends or receives a message, the handler is used to push message to the shard according to the current thread. Thus, messages produced by the same actor can reorder if it’s migrated to another thread by a scheduler.
Yep, we can restore order in the dumper, but don’t do it now because remote DB is doing it anyway. However, we can add the corresponding option in the future. It’s not trivial, although.
Tracing
TODO
TraceId
This ID is periodically monotonic and fits great as a primary key for tracing entries.
It was accomplished by using rarely (approx. once a year) wrapping timestamp ID component.
TraceId essentially is:
\[ \operatorname{trace\_id} = \operatorname{timestamp} \dot{} 2^{38} + \operatorname{node\_no} \dot{} 2^{22} + \operatorname{chunk\_no} \dot{} 2^{10} + \operatorname{counter} \]
This formula’s parameters were chosen carefully to leave a good stock of spare space for TraceId’s components inside the available set of 63-bit positive integers.
You may see the general idea by looking at the bits distribution table.
From MSB to LSB:
| Bits | Description | Range | Source |
|---|---|---|---|
| 1 | Reserved | 0 | - |
| 25 | timestamp in secs | 0..=33_554_431 | Clock at runtime |
| 16 | node_no | 0..=65_535 | Externally specified node (process) configuration |
| 12 | chunk_no | 0..=4095 | Some number produced at runtime |
| 10 | counter | 1..=1023 | A counter inside the chunk |
The code generating TraceId of course can be optimized by using bit shifts for fast multiplication on a power of two:
trace_id = (timestamp << 38) | (node_no << 22) | (chunk_no << 10) | counter
TraceId uses time as its monotonicity source so timestamp is probably the most important part of the ID.
Note that timestamp has pretty rough resolution — in seconds.
How long you can count seconds inside 25 bits?
\[ \operatorname{timestamp}_{max} = \frac{2^{25} - 1}{60 \dot{} 60 \dot{} 24} = \frac{33554431}{86400} \approx 388 \text{ days} \]
Which is almost a year plus 23 days.
What happens when this almost-one-year term ends?
timestamp starts counting from 0 once again:
TIMESTAMP_MAX = (1 << 25) - 1 // 0x1ff_ffff
timestamp = now_s() & TIMESTAMP_MAX
This means that primary key is guaranteed to act as a unique identifier for one year.
To keep an order of entries between monotonic periods of TraceId use some fully monotonic (but not necessarily unique) field as a sorting key for your entries (created_at or seq_no / sequential_number).
TraceId with such timestamp part is well optimized to produce a lot of entities worth querying for only a limited period of time: logs, dumps or tracing entries.
However you’re able to store such entries as long as you like and use data skipping indices for quick time series queries.
To make IDs unique across several instances of your system without any synchronization between them node_no ID component should be externally specified from the system deployment configuration.
TODO: actualize information about thread_id: it’s not used by elfo, but appropriate way to generate trace_id in other systems that want to interact with elfo.
thread_id shares bit space with counter. At the start of the system you should determine how much threads your node could possibly have and choose appropriate \( \operatorname{counter}_{max} \) according to that.
Previous components segregated entries produced by separate threads on every instance of the system at different seconds.
To create multiple unique IDs during a single second inside a single thread we use counter ID component.
Let’s calculate how much records per second (\( \operatorname{RPS}_{max} \)) allows us to produce counter with the bounds we’ve chosen.
Assuming we have 32 threads:
\[ \operatorname{RPS}_{max} = \frac{2^{22} - 1}{\operatorname{threads\_count}} = \frac{2^{22} - 1}{2^{5}} \approx 2^{17} \approx 1.3 \dot{} 10^{5} \text{ } \frac{\text{records}}{\text{second}} \]
Which seems more than enough for the most of the applications.
Note that counter is limited to be at least 1 to keep the invariant: \( \operatorname{id} \geqslant 1 \).
Every other component of TraceId could be zero.
Tokio Console
tokio-console is a diagnostics and debugging tool for async Rust programs. It provides a TUI to inspect the state of async tasks and resources in a running tokio runtime.
Elfo integrates with tokio-console by naming all tasks that run actors or spawned by elfo::task::spawn_blocking() or elfo::task::Builder:

Firstly, add console-subscriber to dependencies and enable the tokio-tracing feature of elfo:
[dependencies]
elfo = { version = "0.2.0-alpha.21", features = ["tokio-tracing"] }
console-subscriber = "0.5.0"
Secondly, we need manually initialize the tracing subscriber instead of letting elfo do it for us:
let (blueprint, scope_filter, capture_layer) = elfo::batteries::logger::new();
tracing_subscriber::registry()
.with(console_subscriber::spawn())
.with(capture_layer.with_filter(scope_filter))
.init();
loggers.mount(blueprint);Finally, compile with --cfg tokio_unstable to opt into tokio’s unstable task instrumentation:
RUSTFLAGS='--cfg tokio_unstable' cargo run
That’s all! Now we can run tokio-console to run the TUI and connect to our application.
Check this example for a complete code sample.
Protocol Evolution
It’s hard to update all nodes in distributed systems simultaneously. Firstly, it requires synchronization of releases and teams. Secondly, it means all nodes become unavailable until the update is finished, which can be highly unpleasant for users.
An alternative approach is updating nodes one by one without any kind of locks between them. However, they can become incompatible with each other because the communication protocol has evolved. That’s where a protocol evolution appears. If a message is sent to another node, we should be more careful when changing it.
Communication is based on the msgpack format. It’s close to JSON, but binary encoded and more feature-rich: it supports arbitrary map keys, special values of floats (NaN, ±inf), and binary data. However, the ability to evolve is the same, so the rules of evolution are also similar.
It’s worth noting that the compatibility of nodes can be checked automatically on a per-message basis (because it’s known where a message is used on the sender and receiver part). However, it’s unimplemented right now.
The common principle
Messages are defined in so-called protocol crates. They shouldn’t contain any logic, only message definitions and convenient constructors, getters, and setters for them. To understand the common principle of evolution, it needs to distinguish nodes that send a message from those that receive it. Senders and receivers are compiled with different versions of the same protocol crate.
The common principle states: senders should send a more specific version of a message than receivers accept.
In this way, if a message in the protocol becomes more specific (e.g., it gets more fields), then senders must be updated first. And, vice versa, if a message becomes less specific (e.g., losing fields), receivers must be updated first. Some changes allow any orders of updating; see the next section for details.
In the case of downgrading nodes, the update order is the opposite.
Let’s consider some example of evolution:

It’s a simple example of evolution with only adding required fields, but it helps to understand the common principle. Providing more fields from a sender than a receiver expects is always acceptable because a receiver can skip these fields during deserialization. If a receiver is updated first, it will expect more fields, and deserialization will fail.
This principle can be propagated to multiple updates as well:

At step 2, the message becomes more specific, so senders are updated first. At step 4, the message becomes less specific, so receivers are updated first.
Examples
| Action | Current version | Next version | Update ordering |
|
Adding a new required field |
|
|
Sender, Receiver |
|
Adding a new optional field |
|
|
Any |
|
Renaming a field |
|
|
Receiver, Sender |
|
Removing a required field |
|
|
Receiver, Sender |
|
Promotion of numbers1 |
|
|
Any |
|
(Un)wrapping into a newtype |
|
|
Any |
|
Adding a new variant |
|
|
Receiver, Sender |
|
Renaming a variant |
|
|
Receiver, Sender |
|
Removing a variant |
|
|
Sender, Receiver |
|
Replacing a field with an union (a untagged enumeration) |
|
|
Any |
|
Removing a variant |
|
|
Sender, Receiver |
|
Enumerations with |
|
|
Receiver, Sender |
-
Promotion to/from
i128andu128doesn’t work due tomsgpack’s implementation details. ↩
Functional Testing
When testing actors, we are rarely interested in their internal state directly. What matters is observable behavior: given a sequence of incoming messages, what messages does the actor produce? This is functional testing at the scale of a single actor group.
These tests exercise the actor through its public protocol, exactly as any other actor in the system would, thus they belong in tests/ rather than src/. That keeps them separate from unit tests for internal helpers, which live in src/.
Setup
Add the test-util feature to elfo in Cargo.toml:
[dev-dependencies]
elfo = { version = "0.2.0-alpha.21", features = ["test-util"] }
tokio = { version = "1", features = ["rt", "macros"] }
Note: test-util exposes elfo::test, additional constructors for messages, and tokio/test-util which let control time in tests. It is intended only for tests; the feature warning printed at startup reminds you not to enable it in production builds.
A minimal example
Note: the full code for this example is available in the elfo repository.
Consider a simple summator actor that accumulates values and responds to summary requests:
#[message]
pub struct Increment;
#[message]
#[derive(PartialEq)]
pub struct Added(u32);
#[message(ret = u32)]
pub struct Summarize;
#[derive(Debug, Deserialize)]
pub struct Config {
step: u32,
}
async fn summator(mut ctx: Context<Config>) {
let mut sum = 0;
while let Some(envelope) = ctx.recv().await {
msg!(match envelope {
Increment => {
let step = ctx.config().step;
sum += step;
let _ = ctx.send(Added(step)).await;
}
(Summarize, token) => {
ctx.respond(token, sum);
}
})
}
}
pub fn new() -> Blueprint {
ActorGroup::new().config::<Config>().exec(summator)
}The corresponding functional smoke test uses elfo::test::proxy(blueprint, config) to start the actor group in an isolated topology and get a dedicated handle to communicate with the actor group:
#[tokio::test]
async fn it_works() {
// Note: `RUST_LOG=elfo` can be provided to see all messages in failed cases.
// Define a config (usually using `toml!` or `json!`).
let config = toml::toml! {
step = 20
};
// ... or provide the default one.
let _config = elfo::config::AnyConfig::default();
// Wrap the actor group to take control over it.
let mut proxy = elfo::test::proxy(summators::new(), config).await;
// How to send messages to the group.
proxy.send(Increment).await;
proxy.send(Increment).await;
// How to check actors' output.
assert_msg!(proxy.recv().await, Added(15u32..=35)); // Note: rhs is a pattern.
assert_msg_eq!(proxy.recv().await, Added(20));
// How to check request-response.
assert_eq!(proxy.request(Summarize).await, 40);
}Asserting messages
assert_msg! and assert_msg_eq! extract a typed message from an Envelope and check it, panicking with a clear diagnostic if the check fails.
// Pattern matching — ranges, wildcards, and guards are all valid.
assert_msg!(proxy.recv().await, Added(15u32..=35));
// Exact equality — requires PartialEq on the message type.
assert_msg_eq!(proxy.recv().await, Added(20));The key difference: assert_msg! takes a Rust pattern (so ranges, nested destructuring, and if guards work), while assert_msg_eq! takes a value and uses assert_eq! under the hood.
See also elfo::test::extract_message, elfo::test::extract_request to extract messages from envelopes to further check them with custom logic.
Synchronization
proxy.sync().await tries to ensure the actor has processed all messages sent so far. It’s not needed for tests using .await communication (e.g. recv, send), but it helps when asserting the absence of output with try_recv():
proxy.send(Increment).await;
proxy.sync().await;
// It's true if the actor sent nothing.
assert!(proxy.try_recv().await.is_none());Timeouts
proxy.recv().await panics if no message arrives within the timeout (default: 150 ms). Importantly, this timer runs on the real wall clock, isolated from tokio’s mocked time, so tokio::time::pause() does not stall recv. The timeout can be changed with proxy.set_recv_timeout(duration), but this is rarely needed: tests that use mocked time typically don’t need to tune it either, since the real clock keeps ticking regardless.
Subproxies
Actors can use send_to or request_to with a specific address rather than the routing system. To test those paths, create a subproxy:
#[tokio::test]
async fn it_uses_subproxies() {
let config = toml::toml! { step = 20 };
let mut proxy = elfo::test::proxy(summators(), config).await;
let mut subproxy = proxy.subproxy().await;
assert_eq!(subproxy.request(Summarize).await, 0);
assert!(proxy.try_recv().await.is_none());
// `send(..)` and `request(..)` always send messages to the original proxy.
subproxy.send(Increment).await;
assert!(subproxy.try_recv().await.is_none());
assert_msg_eq!(proxy.recv().await, Added(20));
}The subproxy has its own address, so the actor can address replies back to it specifically. Messages sent through subproxy.send() still go to the original actor; only the return address differs.
Reconfiguration
To test how an actor reacts to config changes, send an UpdateConfig message carrying a new AnyConfig. The actor receives ConfigUpdated as usual, and ctx.config() returns the new values from that point on. See the reconfiguration section for how this works at the system level.
use elfo::{config::AnyConfig, messages::UpdateConfig};
let new_config = AnyConfig::deserialize(toml::toml! { step = 42 }).unwrap();
proxy.send(UpdateConfig::new(new_config)).await;UpdateConfig can also be used as a request. The response is Ok(()) on success or Err(ConfigRejected) if the new config fails to deserialize into the actor’s Config type:
let bad_config = AnyConfig::deserialize(toml::toml! { step = -1 }).unwrap();
assert!(proxy.request(UpdateConfig::new(bad_config)).await.is_err());
// Config unchanged after rejection.See ValidateConfig for testing config validation without applying the new config.
Termination
To test graceful shutdown, send Terminate::default() and then wait for the actor to finish with proxy.finished().await. Any messages the actor sends during teardown can still be received after finished() returns, since the proxy mailbox remains open:
use elfo::messages::Terminate;
proxy.send(Terminate::default()).await;
proxy.finished().await;
let envelope = proxy.recv().await;Terminate::default() respects the group’s termination policy. When you need to force-close the mailbox regardless of the termination policy, use Terminate::closing() instead.
Recipes
The previous chapters covered the core concepts of elfo: actors, groups, observability, distribution, and testing. This chapter is different — it is a collection of self-contained, practical guides for common tasks and decisions you will encounter when building real systems with elfo.
Each recipe focuses on a specific question. These chapters assume familiarity with the earlier chapters and can be read in any order.
Project Structure
Although the project structure can be arbitrary, it looks reasonable to provide some advices here:
- Use a separate crate for every actor group.
- It speeds up a build time.
- It helps to isolate code.
- Use separate crates for protocols, where messages are defined. Internal messages (timer ticks, inner group messages etc) are defined inside a group’s crate.
- Actor crates shouldn’t depend on each other. Instead, they should depend on protocol crates.
- It helps to achieve loosely coupling.
- Prefer integration tests (
tests/) over unit tests (mod tests). Unit tests are still fine for internal structures.- Integration tests use no implementation details and relies only on protocols.
- Store libraries (additional code potentially used by multiple actors) separately from actors’ code. It’s ok to depends on protocols in that code, but don’t depend on actors.
libs/in the example below. - Store different parts of a group in dedicated files, it siplifies navigation:
exec()and message handling inactor.rs.- An inner-group router in
router.rs. - A group’s config in
config.rs.
- Store topology definitions separately from actors’ code. Services can share actors. Also, it’s a good place for additional files like systemd units and so on.
services/in the example below.
For instance:
actors/
<actor_name_1>/
src/
mod.rs
actor.rs
config.rs
router.rs
tests/
helpers.rs
test_<name_1>.rs
test_<name_2>.rs
Cargo.toml
<actor_name_2>/
protocol/
src/
lib.rs
Cargo.toml
libs/
<lib_name_1>/
<lib_name_2>/
services/
<service_name_1>/
<service_name_2>/
Cargo.toml
Cargo.lock
rustfmt.toml
Multiple Runtimes
By default, all actors in an elfo system run on a single shared Tokio runtime (the one that drives elfo::init::start). This is usually fine, but sometimes it’s desirable to isolate different actor groups or even individual actors onto their own dedicated runtimes. This is especially useful when some groups are latency-sensitive and should not be affected by other groups.
Registering runtimes
Dedicated runtimes are registered on the Topology via add_dedicated_rt. Each call takes a filter predicate and a tokio::runtime::Handle:
use tokio::runtime as rt;
let producers_rt = rt::Builder::new_multi_thread()
.worker_threads(2)
.build()
.unwrap();
let workers_rt = rt::Builder::new_multi_thread()
.worker_threads(3)
.build()
.unwrap();
let topology = Topology::empty();
// Filters are checked in order; first match wins.
// Actors that don't match any filter run on the default runtime.
topology.add_dedicated_rt(
|meta| meta.group == "producers",
producers_rt.handle().clone(),
);
topology.add_dedicated_rt(
|meta| meta.group == "workers",
workers_rt.handle().clone(),
);The filter receives ActorMeta, so it can be used to filter based on actor’s key or group’s name. Filters are evaluated in registration order and the first match wins. Actors whose group matches no filter are spawned on the default runtime (the one that drives elfo::init::start).
Thread accounting
When building a system with multiple runtimes, it is useful to name all threads to distinguish them in logs, profilers and so on:
fn start_runtime(name: &str, workers: usize) -> rt::Runtime {
use std::sync::atomic::{AtomicUsize, Ordering};
let name = name.to_string();
let worker_idx = AtomicUsize::new(0);
rt::Builder::new_multi_thread()
.worker_threads(workers)
.enable_all()
.thread_name_fn(move || {
let idx = worker_idx.fetch_add(1, Ordering::SeqCst);
format!("{name}#{idx}")
})
.on_thread_start(|| {
// A good place to configure thread affinity and set scheduler
// policy, e.g. `SCHED_FIFO`.
//
// Count threads in order to distinguish between workers and
// blocking ones: first `workers` threads are workers, the rest are
// blocking threads.
})
.build()
.unwrap()
}With this setup the first worker thread of the workers runtime will be named workers#0, the second workers#1, and so on.
Run ps -T -p $(pidof multi_runtime) to ensure all runtimes are started:
PID SPID TTY TIME CMD
2163285 2163285 pts/1 00:00:00 multi_runtime
2163285 2163319 pts/1 00:00:00 producers#0
2163285 2163320 pts/1 00:00:00 workers#0
2163285 2163321 pts/1 00:00:00 workers#1
2163285 2163322 pts/1 00:00:00 workers#2
2163285 2163323 pts/1 00:00:00 default#0
When actors are started, their initial thread is printed in the log message:
2026-02-24 07:50:28.286933519 INFO [7446157725601366017] producers/_ - started addr=2/129338070436 thread=producers#0
Note: actors can be rescheduled to a different thread within the same runtime by tokio’s scheduler, but they never migrate between runtimes.
Runtime lifecycle
The dedicated runtimes must be kept alive for the duration of the system. Because elfo::init::start is an async function, it must be driven by some runtime — this is the default runtime. The dedicated runtimes are created beforehand and shut down after the system terminates:
fn main() {
let (topology, runtimes) = topology();
start_runtime("default", 1).block_on(elfo::init::start(topology));
for rt in runtimes {
rt.shutdown_background();
}
}The dedicated runtimes are only referenced by their handles inside the topology; owning the Runtime values outside and dropping them after start returns is sufficient to ensure clean shutdown.
Full example
Check this example for a complete code sample.
Pattern: ID Generation
It should be noted that ID generation approach which was chosen in your app affects your app’s architecture and overall performance. Here we discuss how to design good ID and show a couple of great ID designs.
Choosing the domain for your IDs
Despite of wide spread of 64-bit computer architecture several popular technologies still don’t support 64-bit unsigned integer numbers completely.
For example several popular versions of Java have only i64 type so you can’t have positive integer numbers bigger than \( 2^{63} - 1 \) without excess overhead.
Therefore a lot of Java-powered apps (e.g. Graylog) have limitations on IDs’ domain.
At some external apps you can gain a couple of problems because of IDs less than 1, e.g. value 0 may be explicitly forbidden.
Avoiding 0 value in IDs simplifies some popular memory optimizations and allows you to use zero values instead of Nullable columns which can improve performance in some databases (e.g. ClickHouse).
This leads us to the following integer numbers’ domain for IDs:
MIN = 1
MAX = 2 ^ 63 - 1 =
= 9_223_372_036_854_775_807 =
= 0x7fff_ffff_ffff_ffff ≈
≈ 9.2e18
Probably today you don’t need to be compatible with such domain-limiting systems but in most cases such limitations are very easy to withstand and there’s no reason for your project not to be ready for integration with such obsolete systems in the future. Such domain allows you to store \( 2^{63} - 1 \) entities which is bigger than \( 9.2 \dot{} 10^{18} \) and is enough to uniquely identify entities in almost every possible practical task. You shouldn’t forget though that a good ID generation scheme is just a trade-off between a dense domain usage and robust sharded unique IDs generation algorithm.
That’s why we recommend using 63-bit positive integers as IDs.
Systems with ECMAScript
In theory JSON allows you to use numbers of any length, but in a bunch of scenarios it will be great to process or display your data using ECMAScript (JavaScript, widely spread in web browsers) and it has only f64 primitive type for numbers so you can’t have positive integer numbers bigger than \( 2^{53} - 1 \) without excess overhead.
This leads us to the following integer numbers’ domain for IDs in systems with ECMAScript:
MIN = 1
MAX = 2 ^ 53 - 1 =
= 9_007_199_254_740_991 =
= 0x1f_ffff_ffff_ffff ≈
≈ 9.0e12
From the other hand you can add an extra serialization step storing your IDs in JSON as strings which will be a decent workaround for this problem.
Properties of your ID generation algorithm
We call generated IDs sequence monotonic if every subsequent ID is bigger than a previous one as a number.
Why monotonic IDs are so great
The app should gain parameters for ID generation algorithm after every restart taking into account previously issued IDs. Monotonic IDs generation allows you to take into account only the most recently generated IDs or don’t bother about existing entries at all.
Most of the modern storages allow you to take a notable performance advance if your data was put down in an ordered or partially-ordered form.
The storage lays down the data according to sorting key which may differ from the primary key (ID).
To perform time series queries on partially-ordered data very quickly one can use the cheapest form of data skipping indices — the minmax index.
Partially-monotonic data can be compressed using specialized codecs very effectively, thanks to storing deltas instead of absolute values. Effective data compression is able to lower storage consumption and increase DB throughput significantly.
This means that you should have a good reason to use non-monotonic IDs.
Level of monotonicity
Depending on the length of monotonic segments in the generated IDs sequence we can divide ID generation algorithms to:
- Fully monotonic — generated ID sequence is monotonic during the whole lifetime of the system (see also IDs produced by DB).
- Periodically monotonic — ID generation algorithm reaches the maximal value for ID several times during the lifetime of the system and starts counting from the beginning of the domain.
This means that the storage would contain a couple of monotonic segments e.g. with data for several months long each (see also
TraceId). - With sharded monotonicity — the app generates IDs monotonically for several segments frequently switching between these segments.
E.g. every actor generates only monotonic IDs but because of concurrent nature of actors’ work the storage should handle a lot of intersecting consecutive IDs inserts (see also
DecimalId).
Monotonicity source
There’re several means to gain monotonic IDs. Your choice of them would affect application restart strategy:
- Using DB. Needs atomic compare-and-set (ScyllaDB) or auto-increment
- Launch number (e.g.
DecimalId). - Time (e.g.
TraceId). Time-series-based (not determined, has advantages limitations).
The reasons for non-monotonic IDs
If ID generation algorithm shouldn’t look predictive because of information security concerns it’s a good reason to use multiplicative hashing or random permutations to generate your IDs.
It’s usually a great idea to apply randomness tests to your IDs in such scenarios.
Please note that really secure IDs would require security algorithms (or at least some versions of UUID). Algorithms mentioned above are for IDs that should just look random.
Common or separate domains for several entities’ IDs
Should we use common ID generator for several entities?
In such scenario IDs for various entities will never intersect so you have no chance to successfully query entity A by ID of entity B by mistake and you essentially have “fail fast” approach on entities’ querying.
Unfortunately common ID generator for several entities will exhaust ID domain more quickly.
Great IDs case study
IDs produced by DB
Probably you did already use AUTO_INCREMENT SQL DDL instruction for primary keys.
The general idea with it is to never generate IDs by ourselves and instead rely on the counter inside the database as a single source of truth.
This means that you don’t know the IDs of entities you’d like to insert before you actually insert them so you should essentially support separate schema just for entities’ “construction stubs” and your app’s latency is bound by DB latency by design.
If you need a cycle reference between entities you’d like to insert you’re most likely in trouble.
If you need database replication you’ll be in trouble too.
Alternative — is to use atomic compare-and-swap integrated into several DB engines, for example Cassandra’s lightweight transactions. IDs produced by DB are great for storing entities appearing with relatively low frequency (probably less than 10000 per second): like users or accounts.
Such approach gives us fully monotonic IDs and uses the whole 63-bit space to store ID’s positive value right away.
DecimalId
Probably your application already has some kind of launch log storing information about release ticket in the issue tracking system, launch time, user initiated the launch, etc.
If you have such entity in your system DecimalId will probably serve to you really good.
This ID has sharded monotonicity.
The primary idea behind DecimalId is to increase ID’s legibility by storing its parts in a separate decimal places.
DecimalId essentially is:
\[ \operatorname{decimal\_id} = \operatorname{counter} \dot{} 10^{10} + \operatorname{generator\_id} \dot{} 10^{5} + \operatorname{launch\_id} \]
This formula corresponds to the following decimal places distribution table:
| Digits | Description | Range | Source |
|---|---|---|---|
| 9 | counter | 1..=922_337_202 | Not synchronized runtime parameter |
| 5 | generator_id | 0..=99_999 | Synchronized runtime parameter |
| 5 | launch_id | 1..=99_999, 0 for tests | Externally specified and consistent across the whole system during a single launch |
The code implementing DecimalId generation can’t use bit shift hack as we did for TraceId, but IDs generated using such schema are much more legible.
You’re able to read their decimal representation like this: cc*ggggglllll (counter, generator ID, launch ID — respectively).
For instance:
ID 14150009200065
ccccggggglllll
▲ ▲ ▲
counter (1415) ─┘ │ │
generator_id (92) ──────┘ │
launch_id (65) ───────────┘
Maximal possible ID value is 922_337_203___68_547___75_807 however counter is limited by 922_337_202 (please note the decrement).
Such trick prevents limiting generator_id (next ID component) by 68_547 (now it’s limited by 99_999).
Note that \( \operatorname{counter}_{min} = 1 \) to keep the invariant: \( \operatorname{id} \geqslant 1 \) because every other conmonent of DecimalId could be zero.
Every time system produces more than \( \operatorname{counter}_{max} \) elements it requests persistent synchronized counter global for the whole system for the next generator_id.
This increment happens at the every start of the app and only once for every \( 9.2 \dot{} 10^{8} \) records so contention on it is negligible.
At every launch of your app launch_id should be taken from the persistent launch log of the system.
To make deployment more robust we recommend generating launch_id outside of the app in the deployment configuration.
launch_id = 0 should never appear in production records and may only be used for testing.